校准概率机器:SDD 与 Skill 如何重新定义 AI 时代的元编程边界
校准概率机器:SDD 与 Skill 如何重新定义 AI 时代的元编程边界
从 Python 元类到 BDD Scenario,约束系统的设计者才是真正的架构师
元编程的古典定义及其天花板
元编程(Metaprogramming)在软件工程中有一个精准的定义:用代码操纵代码,用结构描述结构,让程序在运行时或编译时自动完成原本需要手工编写的工作。
Python 生态是古典元编程的最佳展示场。
Django 的 ModelBase 元类是其中最具代表性的案例:当你定义一个继承自 models.Model 的类时,ModelBase.__new__ 会在类对象被创建的瞬间介入——它扫描所有 Field 描述符,注册到 _meta 容器,生成数据库迁移所需的元信息,并将该类绑定到 ORM 的查询管理器上。开发者写下的十行类定义,在 Python 解释器的元类机制下,展开为数百行的运行时行为。
Flask 的路由装饰器是另一种形态的元编程:@app.route("/api/v1/users") 不是一个注释,不是一个标记,而是一次运行时的注册行为——它在函数对象被定义时立即将其写入应用的 URL 规则树,并附上 HTTP 方法约束、参数提取规则和视图函数引用。元编程将「声明意图」与「完成注册」合并成了一个动作。
这些机制的工程价值是真实的:它们消除了大量重复的样板代码,将框架的使用成本压缩到极低的水平。然而,古典元编程有一条无法逾越的边界——
它理解语法,但不理解语义。
ModelBase 知道你定义了 CharField(max_length=100),但它不知道这个字段代表「用户真实姓名,须经实名认证系统二次校验,且不得与历史记录重复」。
Flask 的路由系统知道 /api/v1/users 接受 POST 请求,但它不知道这个接口「仅限内部服务调用,须携带服务间认证令牌,且每个 IP 每分钟限流 100 次」。那些关于业务规则、安全约束、数据治理的核心知识,始终游离在元编程机制之外,只能由人工逐处填补。
开发者,因此成为了一台永不停歇的肉身编译器:接收高层的业务语义,输出低层的语法结构,无休止地循环。
元编程范式的转变——从 Code→Code 到 Intent→System
大型语言模型的出现,在古典元编程的天花板上打开了一道缺口。
这道缺口的本质,是执行层的替换:LLM 可以直接理解人类意图,并将其转化为结构化的可执行实现。
那道原本只能由人类开发者手工搭建的「语义→语法」桥梁,LLM 可以在数分钟内独立完成。范式从 Code → Code(用代码描述规则,Python 解释器执行规则)跃迁为 Intent → System(用自然语言描述意图,LLM 生成系统)。
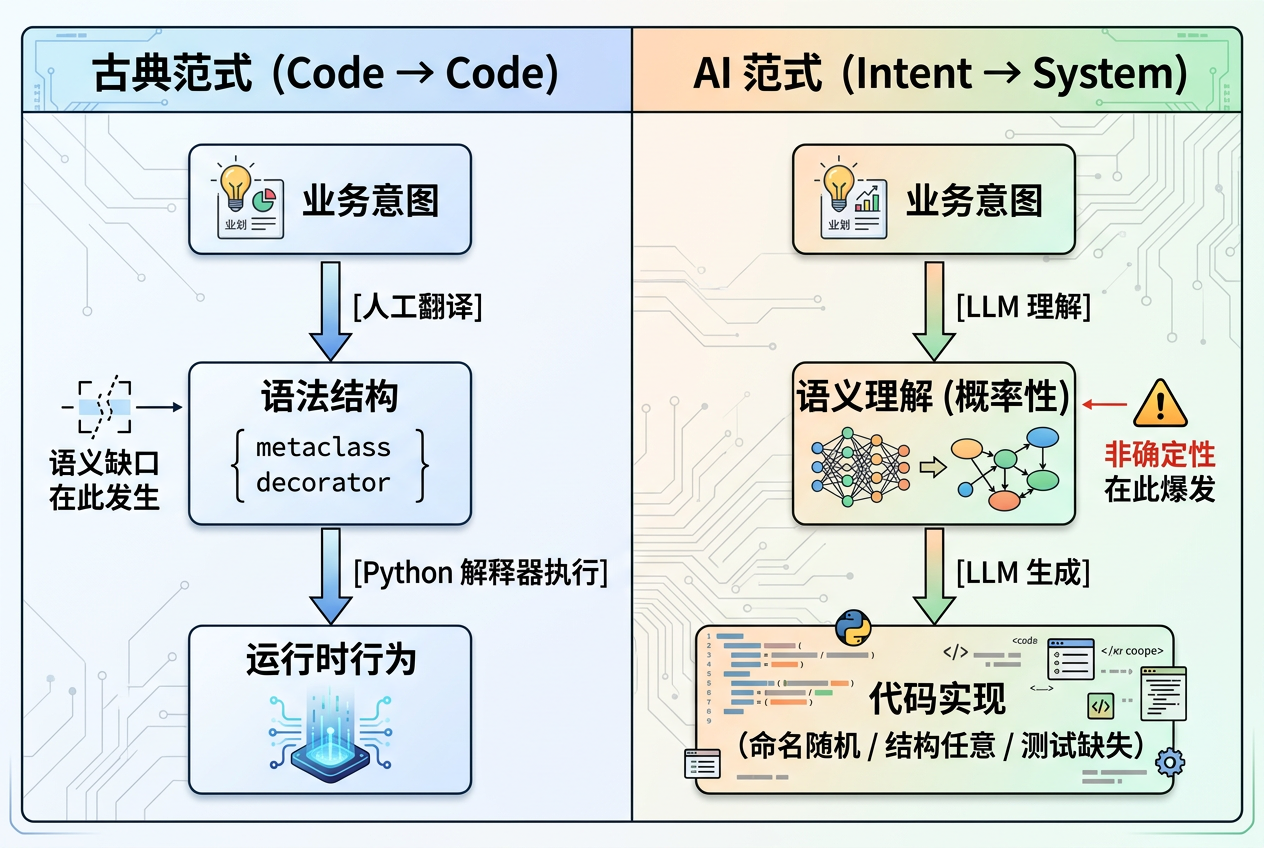
然而,跃迁同时带来了古典时代从未出现过的新风险:非确定性(Non-determinism)。
古典元编程的执行者是 Python 解释器——它严格、确定、无歧义。在相同的元类定义下,每一次生成的运行时行为都完全一致。而 LLM 是一台概率机器。它对同一个意图的每一次理解,都可能在细节上产生漂移:函数命名今天叫 get_alb,明天叫 fetch_alb_instance;测试今天写了,明天在另一次生成里悄然消失;序列化格式今天返回 JSON,明天换成了嵌套字典。
概率正确与必然正确之间的距离,在规模化工程协作场景中,正是一次生产事故的宽度。
双螺旋解法——SDD 与 Skill 的约束共生
非确定性的解法不是放弃 LLM,也不是更努力地手写提示词。解法是重建一套约束系统,让 LLM 在确定性的边界内运行。
这套系统由两条螺旋构成,各自负责一个层次的约束。
3.1 SDD:Spec 是 AI 时代的元代码
Spec Driven Development(规范驱动开发)的核心工具,是 BDD 格式的 Scenario。它是一种介于自然语言和形式逻辑之间的约束语言——不描述「怎么做」,只断言「做完之后世界是什么状态」。
以 gamecloud-mcp 项目的 ALB 负载均衡器查询工具为例,其 spec.md 包含如下 Scenario:
Requirement: ALB 列表查询
系统 SHALL 提供按条件查询阿里云 ALB 负载均衡器列表的能力。
Scenario: 按项目查询 ALB 列表
- WHEN 用户调用
search_alb_by_project工具,提供project参数- THEN 系统返回该项目下所有 ALB 实例的精简信息列表
Scenario: 缺少必选参数 project
- WHEN 用户调用查询工具但未提供
project参数- THEN 系统返回参数校验错误
这两条 Scenario 字数不超过五十,但每个词都承载着精确的工程含义:
SHALL(规范中隐含的强制语气):这不是建议,是硬性约束WHEN:触发条件的精确边界——什么输入、什么调用路径THEN:可验证的结果断言——不是「应该差不多返回一些数据」,而是「返回该项目下所有 ALB 实例的精简信息列表」project在第一条中出现、在第二条中缺失:两条 Scenario 共同确立了project是必选参数这一事实
当 LLM 读到这两条约束时,它的自由度被大幅压缩:函数必须叫 search_alb_by_project(WHEN 已指定),project 必须是必选参数(两条 Scenario 共同锁死),返回值必须是精简字段而非完整详情(THEN 已明确)。Spec 将模糊的自然语言意图提升为形式化的约束断言——这正是元编程的本质:用结构约束结构。
Spec 是 AI 时代的元代码。只是它的执行者,不再是解释器或编译器,而是 LLM。
3.2 Skill:架构规范的强制执行器
Spec 锁死了「做什么」,但它无法约束「怎么做」——代码骨架、命名惯例、序列化格式、测试规范,这些属于工程实现层的约束,需要第二条螺旋。
Skill 是一套元约束系统,以 SOP(标准操作程序)的形式,强制规定 LLM 在生成每一个工具时必须遵守的架构规则。
继续以 gamecloud-mcp 项目的 ALB 负载均衡器查询工具为例,cloud-resource-query-tool Skill 的代码生成步骤(Step 5)定义了如下骨架:
# FastMCP 实例命名:必须遵循 "<provider>/<resource>/" 格式
alb_tools = FastMCP(name="aliyun/alb/")
# FieldSelector 必须分离:LIST 返回精简字段,GET 返回完整字段
LIST_FIELDS = FieldSelector([
"load_balancer_id", "name", "region", "project", "mode", "dns_name",
])
GET_FIELDS = FieldSelector([
"load_balancer_id", "name", "region", "project", "mode", "dns_name",
"zone_mappings", "load_balancer_billing_config", "access_log_config",
])
# 序列化器:必须使用 @with_toon_serializer,不得使用裸 dict
@alb_tools.tool(description="按项目查询 ALB 列表")
@with_toon_serializer # ← 强制约束,不可省略
async def search_alb_by_project(project: str) -> dict[str, Any]:
...
每一行都是一条不可协商的架构规则:
- FastMCP 实例命名决定了工具的 MCP 注册路径;
- LIST/GET 字段分离确保了响应体的精简与完整的明确区分;
@with_toon_serializer保证了所有工具的输出格式对 LLM 一致可解析。
Skill 以 SOP 的形式,指导 LLM 同时完成代码生成与任务规划:
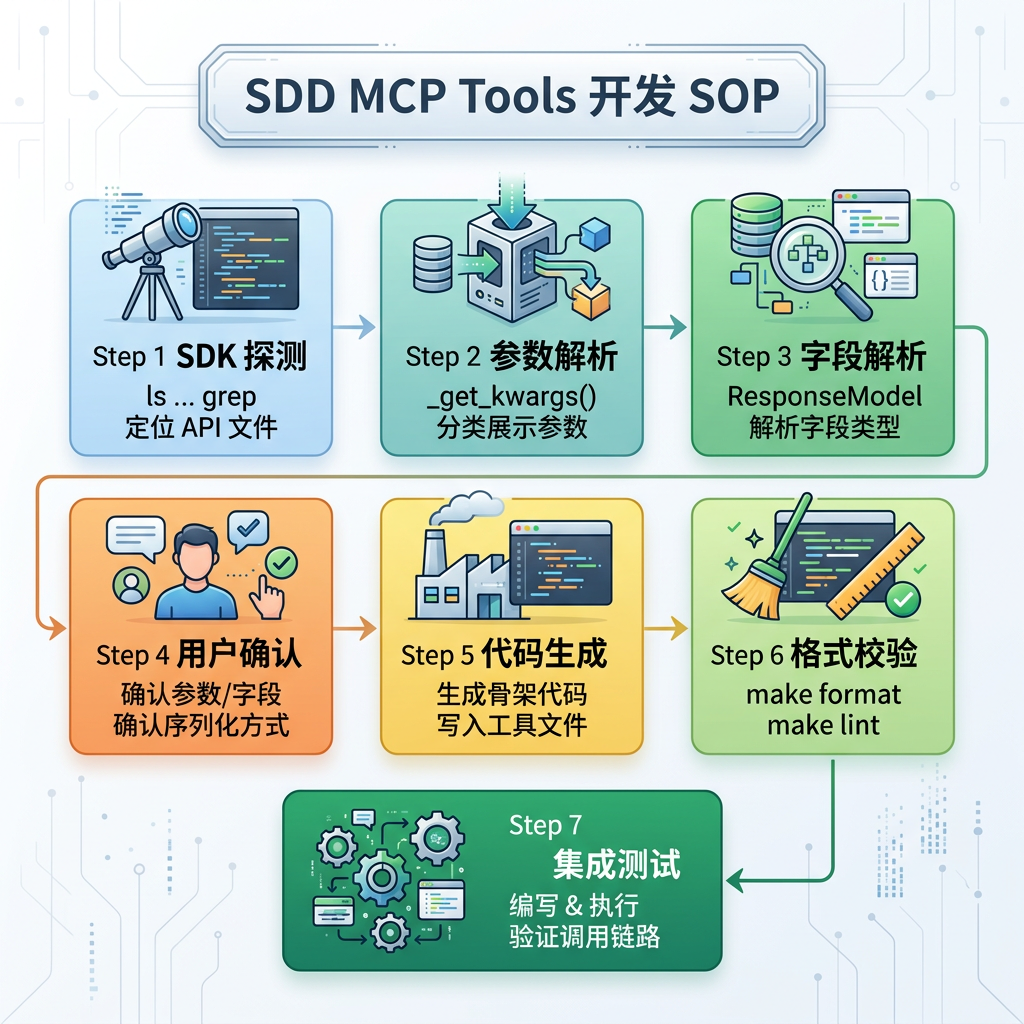
Skill SOP 的价值在于同时规范两件事:代码如何生成,以及 Spec 规划任务如何拆分。在 tasks.md 拟定阶段,Skill 要求每个模块必须包含集成测试任务条目——测试的存在性在编码开始前已被固定,不依赖人工事后判断。
在 SOP 的指引下,LLM 在完成代码生成后,须立即执行测试并验证结果,形成「生成 → 自测 → 修正」的闭环。测试不再是独立的后置工序,而是每个开发任务的内置收尾步骤。
3.3 约束收敛:双螺旋如何收敛不确定性
SDD Spec 与 Skill SOP,各自是一条约束链:Spec 链编码语义规则(锁定行为边界),Skill 链编码架构规则(SOP 固化实现方式)。两者缠绕形成双螺旋——正如 DNA 双链,缺少任何一条,约束结构都是不完整的。
两链叠加,共同将 LLM 的输出空间从无约束逐步收窄至确定性区间:
这不是限制 LLM 的能力,而是对其输出施加工程约束:LLM 的语义理解得到充分发挥,「非确定性」的风险被精确裁剪。在双螺旋的约束下,概率机器(LLM)可以稳定输出确定性的工程成果。
开发者的新位置——设计约束系统本身
在理解了双螺旋解法之后,一个更根本的问题浮现出来:这一切中,人类开发者究竟在做什么?
表面上看,开发者在写 Spec,在写 Skill。但本质上,开发者在做的事情和 Django 核心贡献者设计 ModelBase 元类时做的事情,是同一件事——设计规则,让其他实体(Python 解释器,或 LLM)在这套规则的约束下自动完成工作。
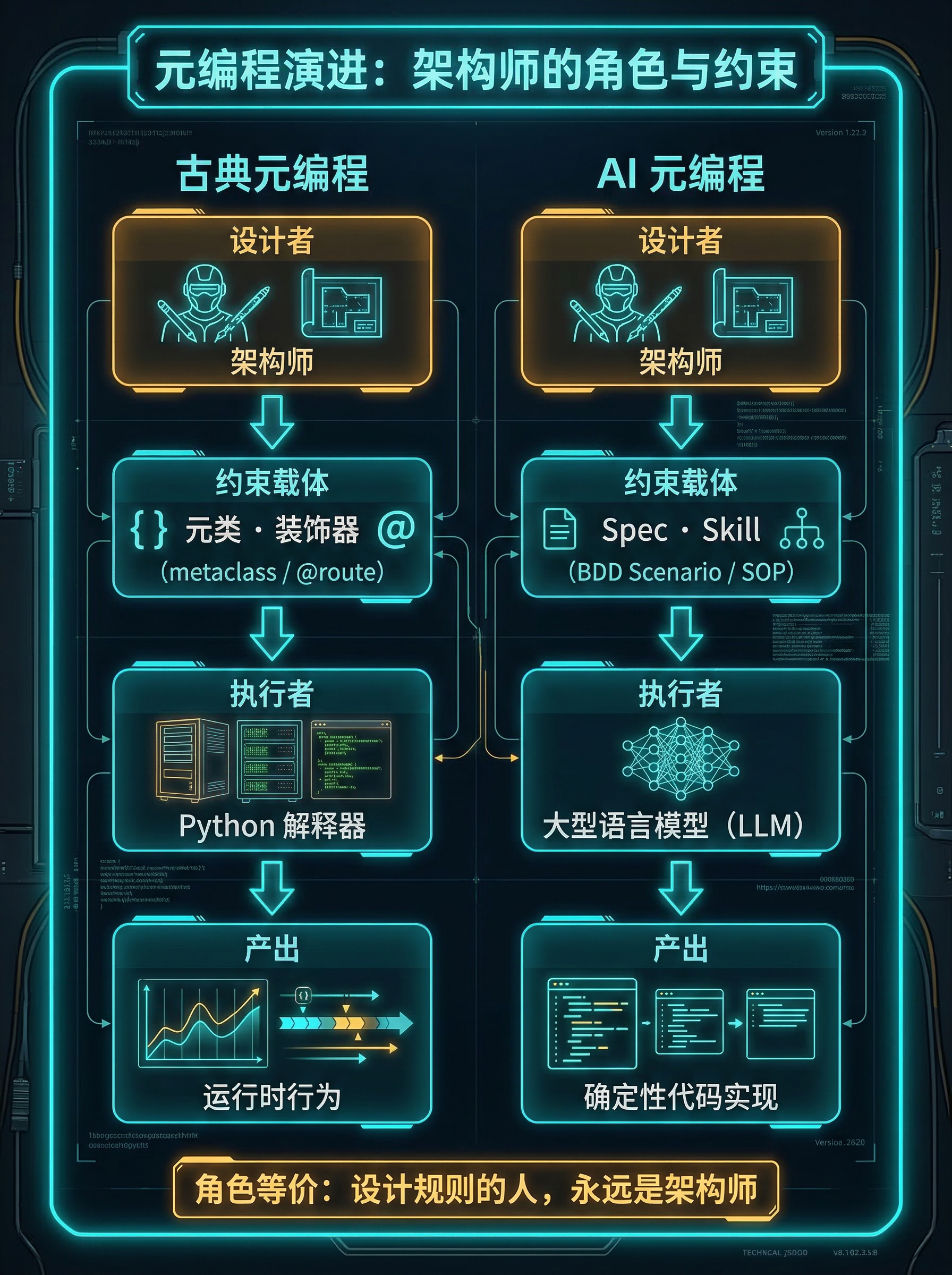
两种范式的差异是媒介和执行者,而非开发者的角色本质。无论是设计 ModelBase 元类、编写 ALB Spec,还是定义 cloud-resource-query-tool Skill,开发者做的都是同一件事:制定规则,让执行者(Python 解释器或 LLM)在规则边界内自动完成工作。
在 AI 时代,开发者的工作层次从「逐行编写语法结构」上移到了「设计让 LLM 可靠完成翻译的约束体系」。这不是降低了开发者的价值,而是解放了开发者,让他们真正站到了那个更高的位置:约束系统的设计者,秩序的立法者。
媒介从代码变成了 Markdown 文档,执行者从 Python 解释器变成了大型语言模型。但那个位于两层之间的元逻辑——用结构约束结构,用规则驱动执行——从未变过。
变化的是工具,不变的是架构师的职责。