Git Merge Conflicts
前言
在上一篇文章Git 合并代码的不同方式中介绍了 Merge Commit、Squash Merge、Cherry-pick、Rebase Merge 等合并方法的差异和使用场景, 接下来我们继续讨论与 Git 密不可分的另一个话题 -- 代码合并冲突。
为什么会发生代码冲突?
当多个开发者试图编辑相同的内容时, 那么就可能发送代码冲突。例如以下就是典型的代码冲突时的场景:
## 一开始, 我们实现了一个很简单的 a + b 的函数
def add(a, b):
try:
return 0, a + b
except Exception:
return -1, None
## 然后, 有个开发者希望用 contextlib.suppress 替换这个 try-except
from contextlib import suppress
def add(a, b):
with suppress(Exception):
return 0, a + b
return -1, None
## 但是, 另一个开发者又提交了一个 bugfix, 希望修复当 a, b 为字符串时, 结果不符合预期的问题
def add(a, b):
try:
return 0, int(a) + int(b)
except Exception:
return -1, None
当我们分别合并以上两份代码时, 就会出现代码冲突:
def add(a, b):
<<<<<<< HEAD
with suppress(Exception):
return 0, a + b
return -1, None
=======
try:
return 0, int(a) + int(b)
except Exception:
return -1, None
>>>>>>> bugfix
理解冲突的含义
合并和冲突是所有版本管理工具都会存在的正常情况, 在大多数情况下, Git 都可以智能地解决无歧义的合并方案, 但是如果合并有歧义(即冲突), 不像其他的版本控制系统, Git 绝对不会尝试智能解决它。我们必须解决所有合并冲突后, 才能真正完成 2 个分支的合并。
合并冲突的类型
一般情况下, 只有在两个开发者分别修改 1 个文件的相同行时, 或者是一个开发者在修改一份被另一个开发者删除的文件时, 才会出现代码冲突 -- 因为 Git 无法判断哪一个才是正确的。以上这些情况都已经在进行分支合并了, 事实上冲突还可能发生在合并启动之前。
Git 无法启动合并
当 Git 发现当前项目的工作目录或暂存区域发生更改时, 合并将无法启动。当发生以下情况时, 并不是意味着你的代码与其他开发者发生冲突, 反而是与你本地的其他(未保存的)变更发生冲突。想要解决这种状态也很简单, 以下是针对不同情况使用的指令:
git stash> 贮藏(stash)会处理工作目录的脏的状态 —— 即跟踪文件的修改与暂存的改动 —— 然后将未完成的修改保存到一个栈上, 而你可以在任何时候重新应用这些改动(甚至在不同的分支上)。git checkout> 检出(checkout)会恢复工作目录中的文件至未修改的状态, 与 stash 不同, checkout 会直接丢弃当前未完成的修改, 如果你不希望工作内容被丢弃, 请使用git stash。git commit> 提交(commit)会将当前暂存区域的所有变更保存至版本变更记录中。git reset> 重置(reset)会只丢弃当前缓存区域的状态, 而保留工作目录的状态。如果文件不存在于版本库, 那么使用git reset即可将该文件的状态设置为 untracked。
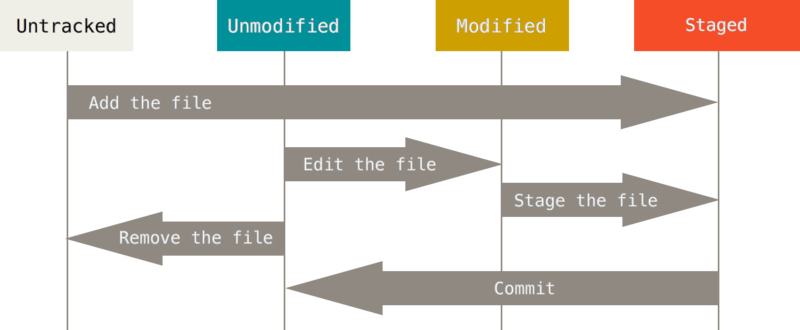
只有所有文件都处于 unmodified 或 untracked 时, Git 才能启动合并。
Git 智能合并失败
当合并过程发生冲突时, 合并将会中止, 此时的代码处于 合并中 的状态。 当这种情况发生时, 代码库将无法进行 pull、push 等操作,直至开发者解决冲突完成合并后(或者中止合并)。
典型的代码冲突例子在前文已有提及, 再次强调, 通常情况下只有在两个开发者分别修改 1 个文件的相同行时, 或者是一个开发者在修改一份被另一个开发者删除的文件时, 才会出现代码冲突。但总会有些我们预料之外的非典型冲突。
Git Squash Merge 冲突
在上一篇文章Git 合并代码的不同方式中有提及, Squash Merge 会将代码提交记录压缩合并为 1个节点, 并追加至当前分支的末尾。使用 Squash Merge 会产生以下的拓扑结构:
H---I---J feature-xxx
/
E---F---G---K----L' develop (where L' == (H + I +J)
/
A---B---C---D master
使用 Squash Merge 后, Git 将不能追踪 feature-xxx 分支 与 develop 分支 之间的关系。如果此时继续在 feature-xxx 分支 开发, 那么很可能会产生不必要的冲突。
最简单的例子, 如果进行 Squash Merge 时代码有冲突, 那么在 Squash Merge 后, 再执行 Rebase 那就会发现相似的冲突需要再次解决。
因为
Squash Merge会丢失新节点 L' 与原分支的关联关系。 Git 无法判断这两份代码之间的关联性(即使你知道它只是被 Squash 了而已)。
Git Rebase 冲突
在上一篇文章Git 合并代码的不同方式中有提及, Rebase(变基) 即变更当前分支的根节点。对于以下的拓扑结构而言:
E---F---G feature-xxx
/
A---B---C---D develop
将 feature-xxx 分支 rebase 至 develop 分支 时, 事实上经历了以下流程:
- 将 E 节点的变更记录提交至 D 节点后
E' rebasing
/
A---B---C---D develop
- 将 F 节点的变更记录提交至 E' 节点后
E'---F' rebasing
/
A---B---C---D develop
- 将 G 节点的变更记录提交至 F' 节点后
E'---F'---G' rebasing
/
A---B---C---D develop
通常情况下, Rebase(变基) 与 Merge(合并) 是一样的, 遇到无歧义的代码合并时会自动完成变基。当变基过程发送冲突时, 变基将会中止, 此时的代码状态与合并冲突时一致。当开发者解决冲突即可继续变基。
但是, Rebase 相对于 Merge 而言具有一定的危险性, 如果分支不经常 Rebase,Rebase期间可能会出现很多合并冲突, 甚至有时候会出现相似的冲突需要解决多次, 甚至出现预期以外的合并结果!
我们首先展示相似冲突需要解决多次的情况, 以上述的拓扑结构为例, 假设我们在 B 节点具有以下代码:
def sum(a, b):
return a + b
并且, 该代码在 D 节点被重构成:
def sum(*args):
result = 0
for arg in args:
result += arg
return arg
此时, 我们在 E 节点中将 B 节点的代码进行了安全性重构:
def sum(a, b):
ai, bi = int(a), int(b)
return ai + bi
在 F 节点又再次进行了安全性重构:
def sum(a, b):
try:
ai, bi = int(a), int(b)
except ValueError:
return 0
return ai + bi
我们现在开始执行 Rebase(变基) 指令:
➜ git rebase master other
意料之内的发生合并冲突:
++<<<<<<< HEAD
+def sum(*args):
+ result = 0
+ for arg in args:
+ result += arg
+ return arg
++=======
+ def sum(a, b):
+ ai, bi = int(a), int(b)
+ return ai + bi
++>>>>>>> E
解决冲突后, E' 节点的代码如下:
def sum(*args):
result = 0
for arg in args:
result += int(arg)
return arg
继续变基, 再次发生合并冲突:
++<<<<<<< HEAD
+def sum(*args):
+ result = 0
+ for arg in args:
+ result += int(arg)
+ return arg
++=======
+ def sum(a, b):
+ try:
+ ai, bi = int(a), int(b)
+ except ValueError:
+ return 0
+ return ai + bi
++>>>>>>> F
再次解决冲突后, Rebase 才真正执行完成。如果我们使用 Merge 进行代码合并, 反而只需要解决 1 次冲突。这种差异的根本原因是由 Rebase 的原理造成的 -- Rebase 可理解为将需要变基的分支的提交在变基目标分支上依次重放。
因此, 想要减少相似问题解决多次的情况, 有以下的途径:
- 遇到冲突时只使用 ours 的改动 > 因为 ours 的改动绝对不会和下一个提交产生冲突 > 不过这种做法有掩耳盗铃的嫌疑。
- 先使用
交互式 Rebase将当前分支的改动Squash(压缩)成 1 个提交, 再执行 rebase > 因为这样就只会产生 1 次提交重放
软件开发中没有银弹, 唯一能避免冲突的方法就是不参与开发。Rebase 虽然灵活, 但是要得到什么就要付出同等的代价 -- 这就是炼金术的等价交换原则!
Git 智能合并陷阱
Git 合并不是万能的, 智能合并不一定能产生符合预期的代码。使用以下的拓扑结构进行介绍:
E feature-xxx
/
A---B---C---D develop
其中 B 节点具有以下的代码:
## -*- coding: utf-8 -*-
def sum(a, b):
return a + b
def factorial(n):
...
随后, D 节点对代码进行了重构:
## -*- coding: utf-8 -*-
def sum(*args):
result = 0
for arg in args:
result += arg
return arg
def factorial(n):
...
与此同时, 在另一个分支 feature-xxx 的 E 节点对代码进行了安全性重构, 同时重新编排了代码:
## -*- coding: utf-8 -*-
def factorial(n):
...
def sum(a, b):
ai, bi = int(a), int(b)
return ai + bi
此时, 如果我们合并 feature-xxx 分支 与 develop 分支 会产生冲突, 但是 Git 提示的冲突内容是很奇怪的。
❯ cat example.py
## -*- coding: utf-8 -*-
<<<<<<< HEAD
def sum(*args):
result = 0
for arg in args:
result += arg
return arg
=======
>>>>>>> other
def factorial(n):
...
def sum(a, b):
ai, bi = int(a), int(b)
return ai + bi
遇到这种情况的代码冲突, 如果不仔细阅读代码将会造成错误的合并结果。
总结
代码冲突在所难免, 在了解冲突发生的原因后精准修复代码是程序员的必备技能之一。通常情况下, Git 已经通过自动合并算法解决了大多数无歧义的代码合并。基本上只有在两个开发者分别修改 1 个文件的相同行时, 或者是一个开发者在修改一份被另一个开发者删除的文件时, 才会出现代码冲突。